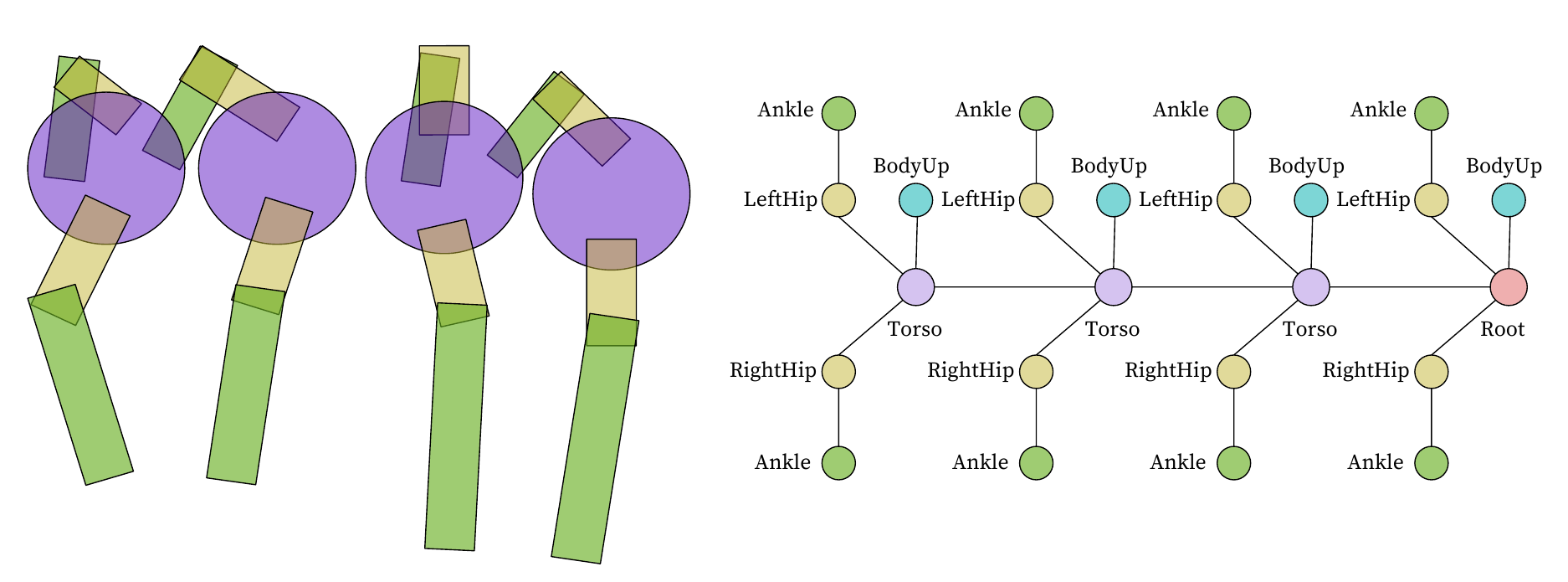
|
|
|
|
Sanja Fidler |
|
|
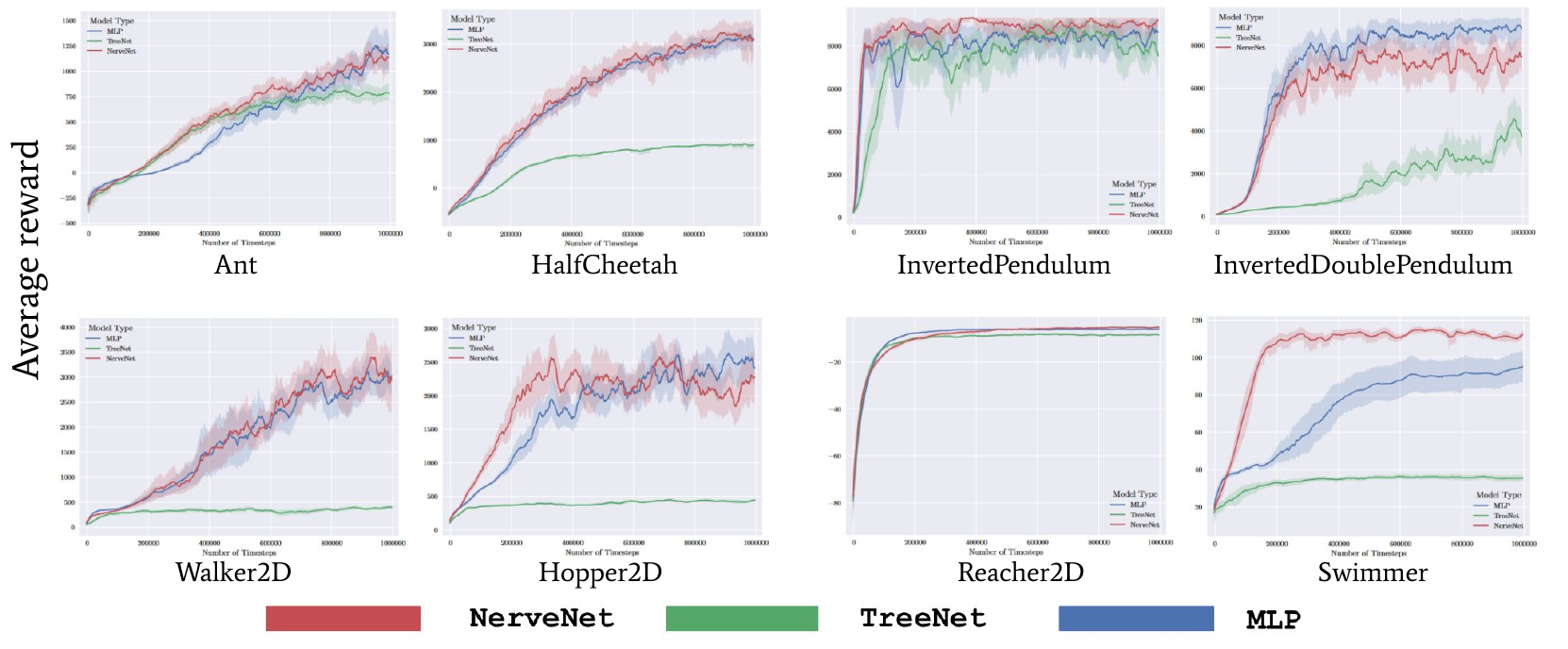 |
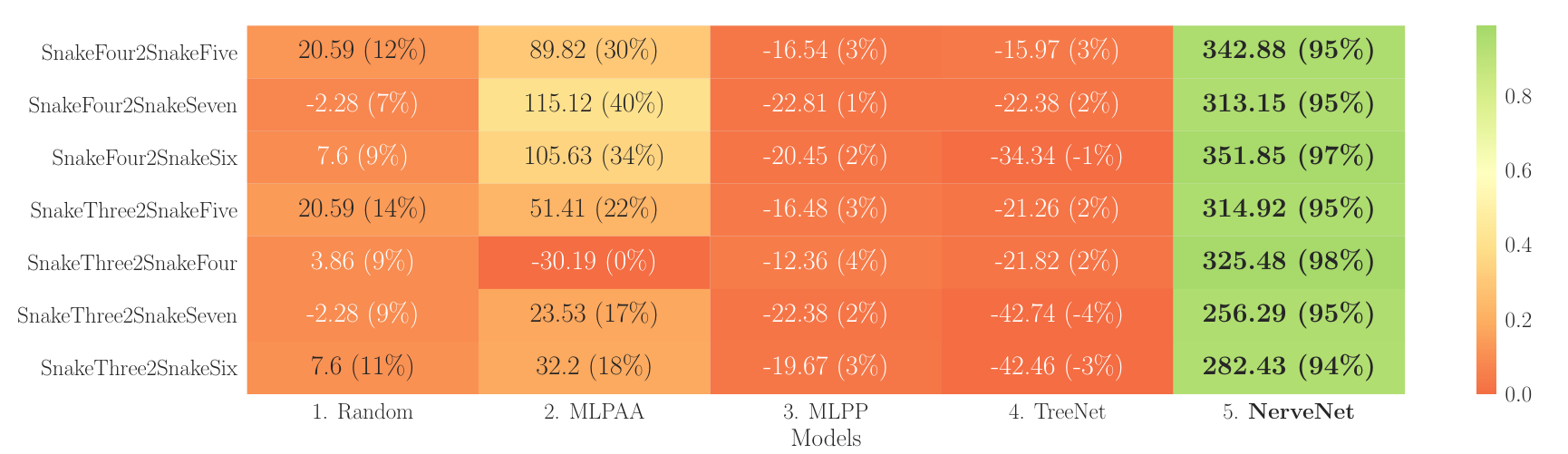 |
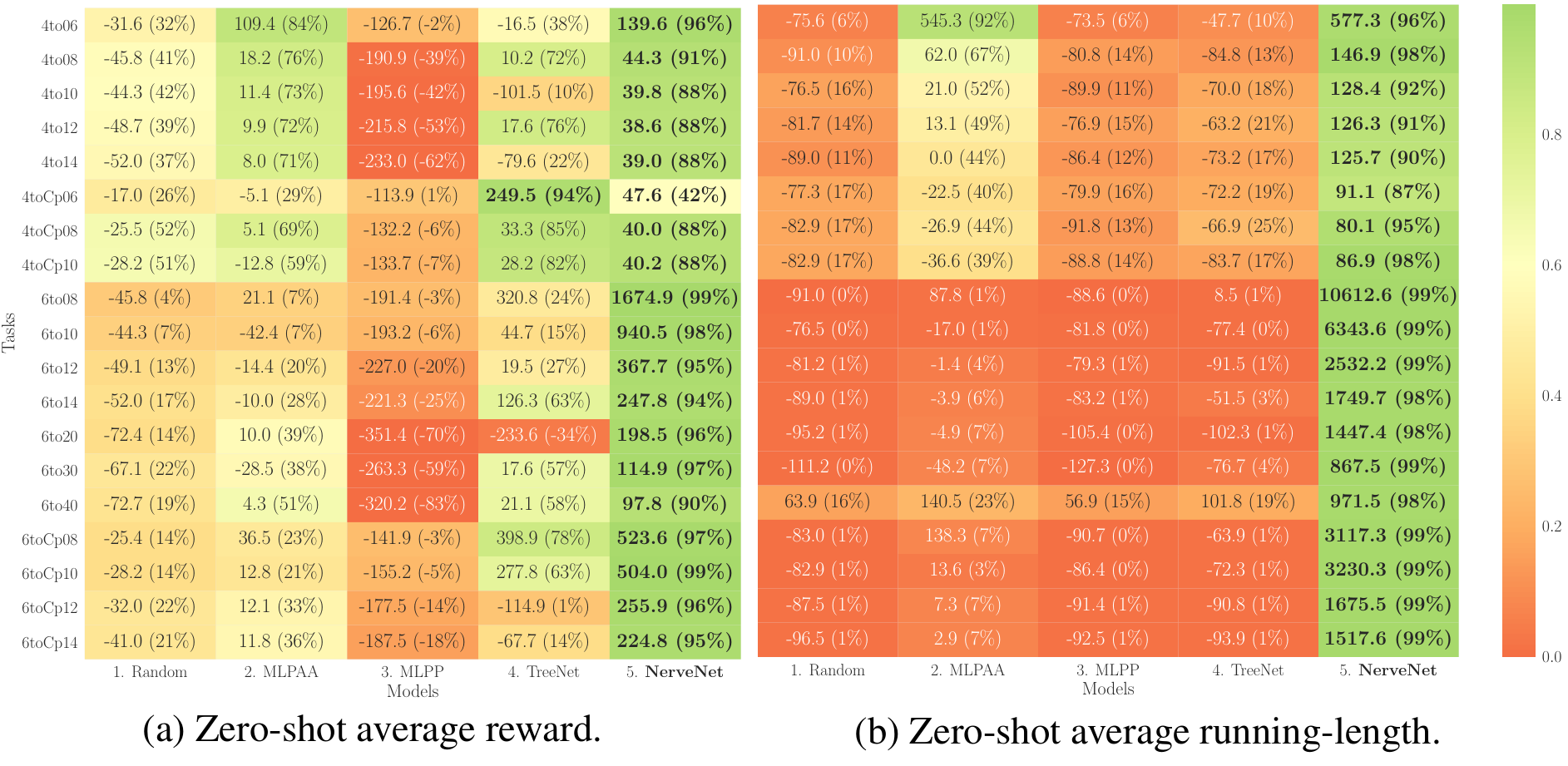 |
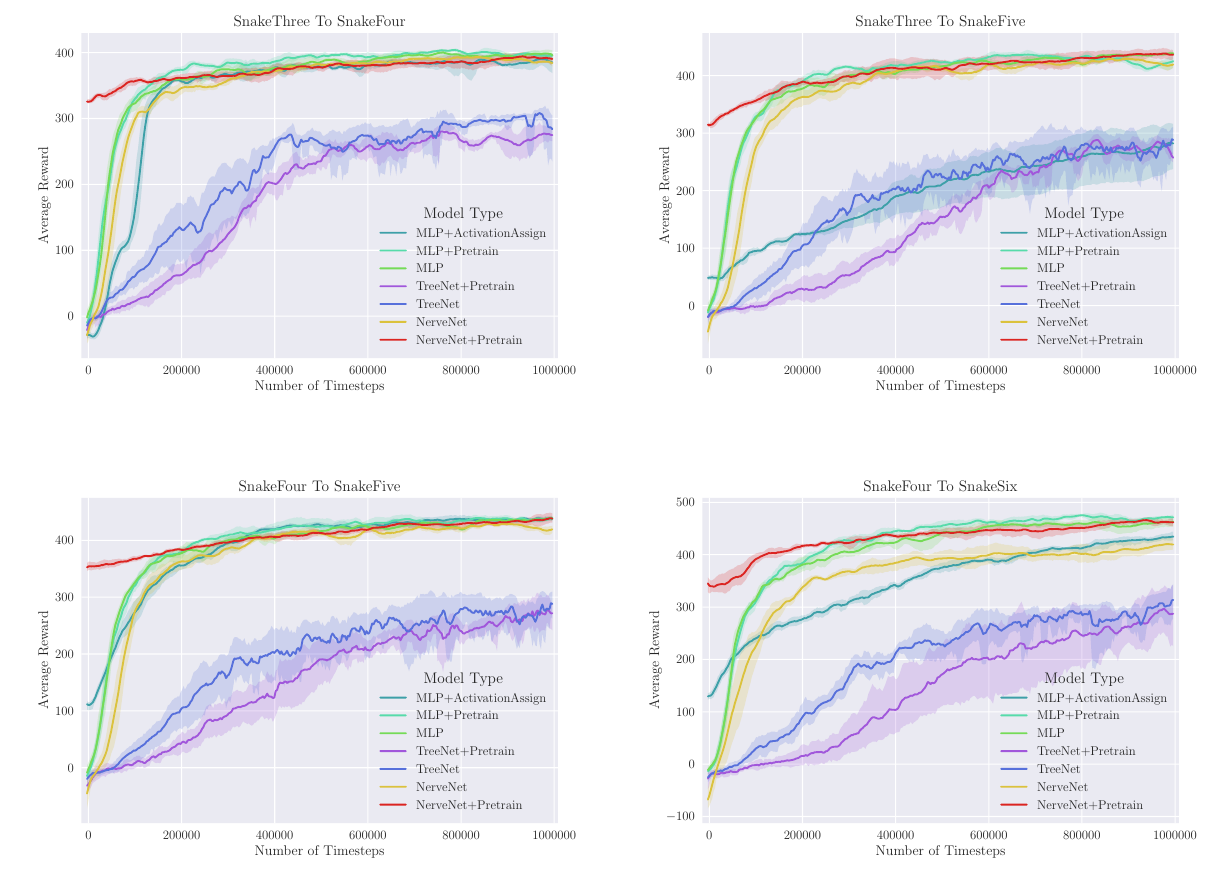 |
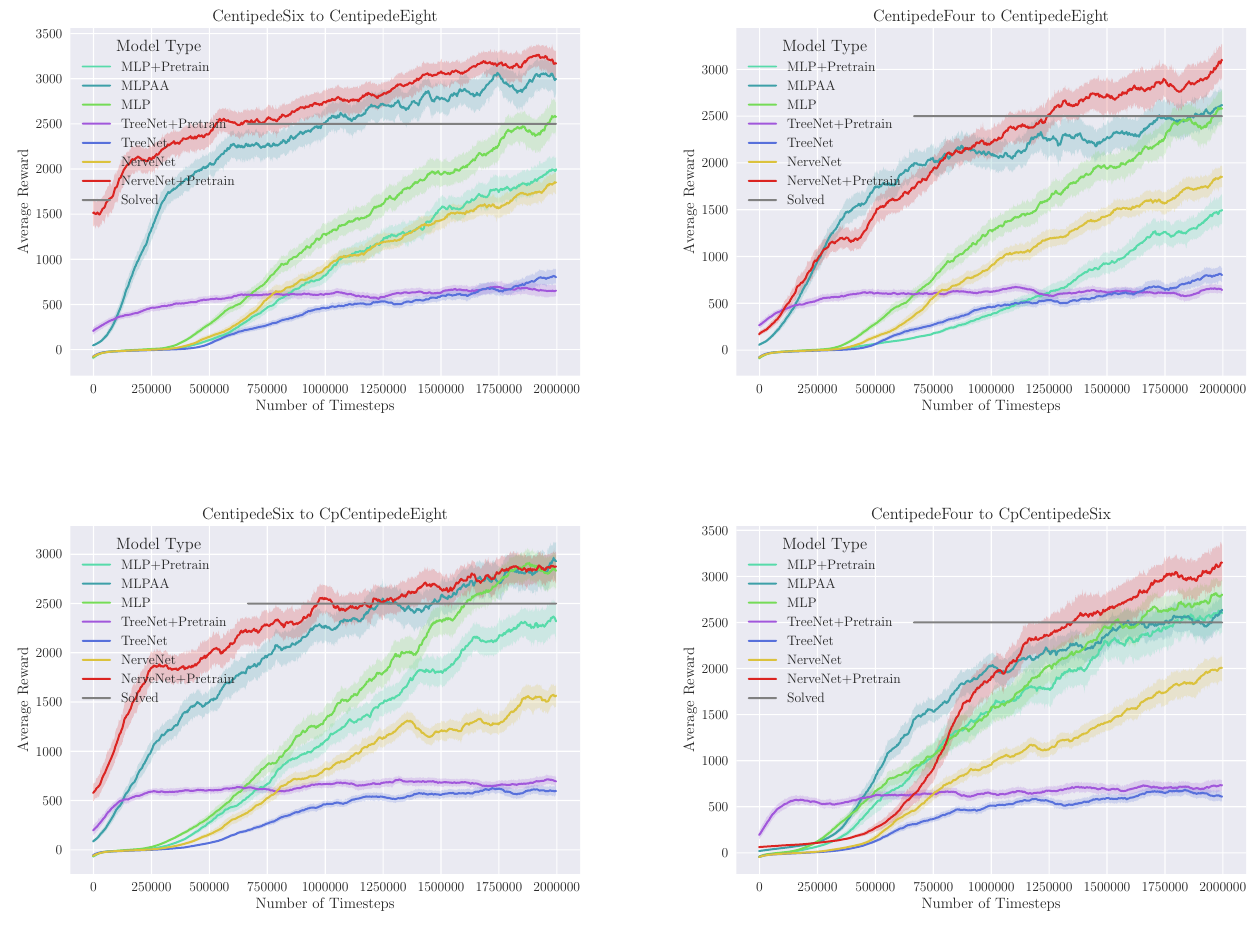 |
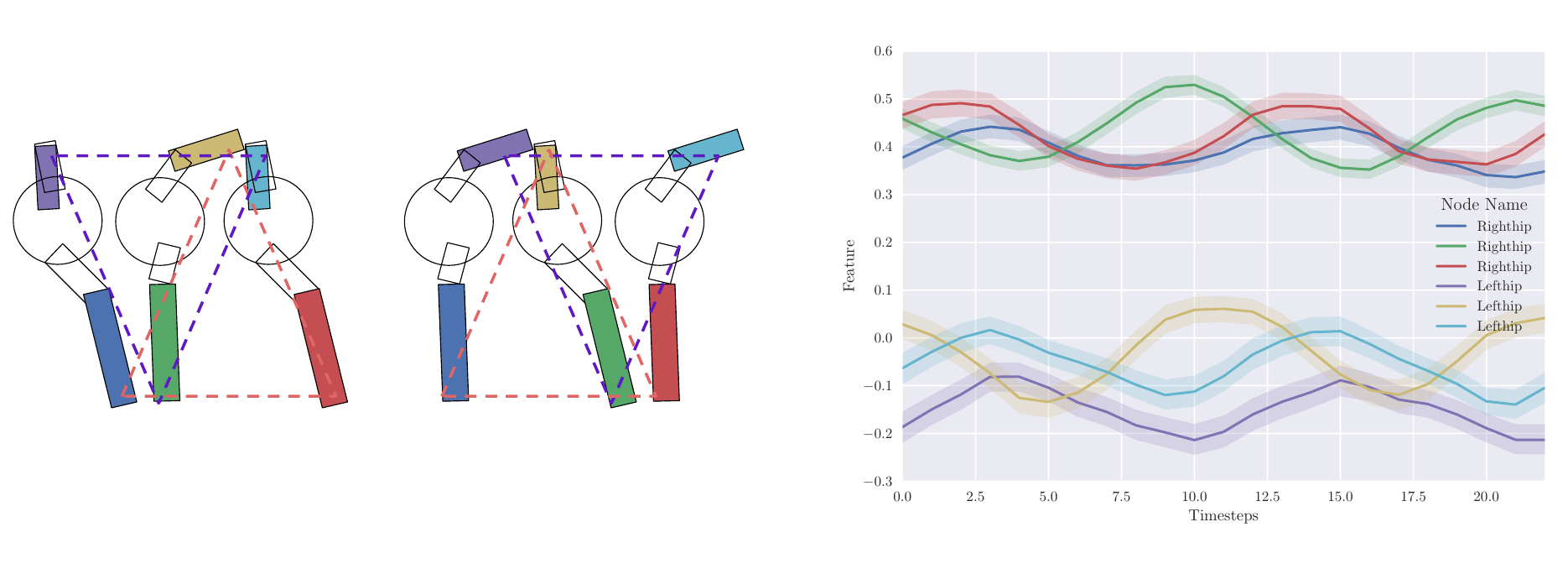 |
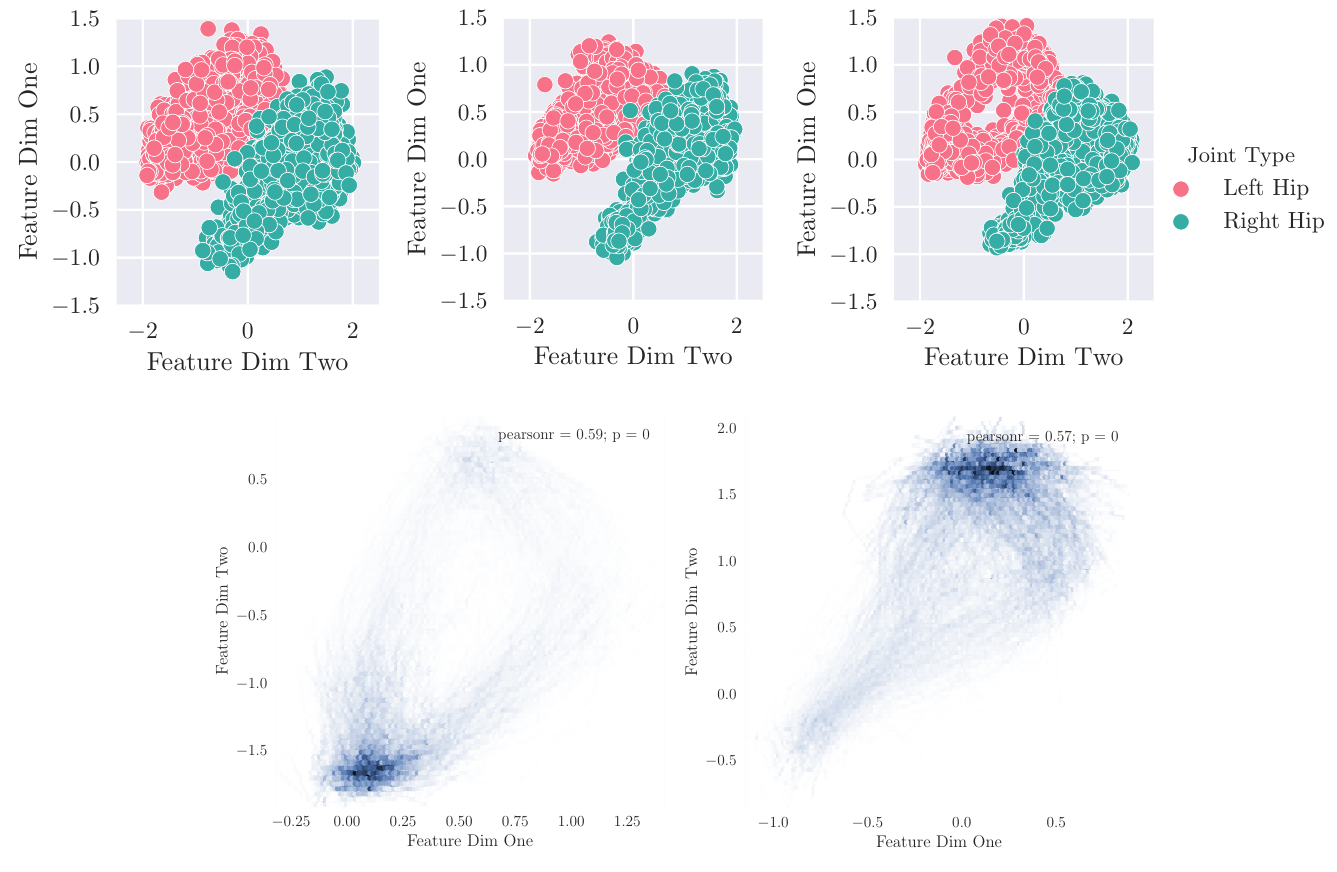 |
 |

|
Citation |
|
Last Update: Nov 16th, 2017 |